Editor: Augusto Radünz do Amaral
Colaboradores: Bruna da Silva Ferreira, Felipe Starling Jardim e Fernanda Cristina Zanotti
Introdução[]
"A estatística é uma coleção de métodos para planejar experimentos, obter dados, organizá-los, resumi-los, analisá-los, interpretá-los e deles extrair conclusões". (Triola, 1998).
A estatística aplicada, segmento ao qual pertence a bioestatística (estatística aplicada às ciências biomédicas), divide - se ainda em dois grandes grupos:
Estatística Descritiva: Descreve um conjunto de dados desde a elaboração da pesquisa até o cálculo de determinada medida.
Estatística Inferencial: Relaciona - se à incerteza. Está integralmente associada ao cálculo de probabilidades, através do qual são feitas projeções para determinada característica, visando "prever" o seu comportamento.
Aplicações Biomédicas da Estatística[]
- As indústrias farmacêuticas desenvolvem fornecem melhores medicamentos a custos menores através de técnicas de controle de qualidade;
- Controle de doenças com o auxilio de análises que antecipam epidemias;
- Indicações, através de cálculos probabilísticos, para mudanças de procedimento para anamnese do paciente;
- Orientação de cruzamentos nos experimentos em melhoramento genético;
- Definição e conclusão sobre a manifestação de características hereditárias.
Tipos de Variáveis[]
A variável é um componente da estatística o qual deseja - se observar de modo a tirar alguma conclusão. As varíaveis são distinguíveis de diversas formas. Quanto ao seu comportamento de causa (variável preditora) ou consequência (variável desfecho). A nossa intenção nesse momento, entretanto, é explicar os diferentes tipos de variáveis e como a escolha de um tipo ou de outro interfere nos resultados de um estudo estatístico. As variáveis são majoritarimente divididas, de acordo com suas características específicas, da seguinte forma:
Variáveis Qualitativas (Categóricas): Se distinguem por atributos específicos, alguma característica não numérica. Podem ser divididas em "nominais" e "ordinais":
- Ordinais: Podem ser organizadas. Há hierarquização entre as características. Ex: classe social, grau de escolaridade, etc.
- Nominais: Não podem ser ordenadas (não possuem ordem), ou seja, não há hierquização entre as características. Ex: sexo, religião, cor dos olhos, número do telefone, etc.
Variáveis Quantitativas: São passíveis de contagem ou mensuração. Podem ser divididas em "discretas" e "contínuas":
- Discretas: Conjunto finito, enumerável de valores possíveis. Ex: número de partos normais.
- Contínuas: Números infinitos de valores possíveis. Podem ser associados a pontos em uma escala contínua. Ex: peso, altura, temperatura, etc.
DICA: Quando houver dificuldades em caracterizar uma variável quantitativa como discreta ou contínua, lembre - se dos termos em inglês many e much. Perceba que na língua inglesa utiliza – se many para objetos cujos valores são finitamente contáveis e much para aqueles infinitamente contáveis. Logo:
- Many: Variáveis quantitativas discretas (ex: número de filhos).
- Much: Variáveis quantitativas contínuas (ex: volume de reserva expiratória).
Distribuições e Frequências[]
Um dos grandes objetivos da estatística aplicada é encontrar padrões comportamentais de um conjunto de dados observados. Isso se faz por meio da síntese dos dados númericos coletados sob a forma de tabelas, gráficos ou quadros.
Dados Brutos: Conjunto de informações (dados) obtidos após coletas sem nenhum tipo tratamento, organização ou síntese.
Rol: Organização (arranjo) dos dados brutos em ordem de frequência (crescente ou decrescente).
Amplitude Total ou Range (R): É a diferenca entre o maior valor observado e o menor valor observado.
Distribuição das Frequências: É o arranjo dos valores e suas respectivas frequências. A partir do qual será mostrado as frequências absoluta, absoluta acumulada, relativa e relativa acumuladas. Todas abordadas de maneira individual adiante.

{kind=link}
Fonte: Claiton E. Amaral, 2013 (Anotações da Aula)
Frequência Absoluta (Fa): Número de vezes que o elemento aparece na amostra.
Frequência Absoluta Acumulada (Fac): Soma das frequências dos valores inferiores ou iguais ao valor.
Frequência Relativa (Fr): Porcentagem do valor observado na amostra.
Frequência Relativa Acumulada (Frac): Soma das frequências relativas dos valores inferiores ou iguais ao valor dado.

{kind=link}
Fonte: Claiton E. Amaral, 2013 (Anotações da Aula)
Histograma: É uma representação gráfica de uma distribuição de frequências por meio de retângulos justapostos verticalmente.
Polígono de Frequências: Método gráfico de representação da distribuição por meio de um polígono. Geralmente está desenhado junto ao histograma.
Medidas de Tendência Central ou Posição[]

{kind=link}
Fonte: Claiton E. Amaral, 2013 (Anotações da Aula)
Média Aritmética (Ma): Soma das observações divida pelo número de observações.
- Populacional: representada pela letra grega u ("mi").
- Amostra: representada por "x barra".
Moda (Mo): É o valor mais frequente em uma distribuição
- Distribuição Amodal: Não há observação com maior frequência.
- Distribuição Unimodal: Uma única observação mais frequente.
- Distribuição Bimodal: Duas observações com maior frequência.
Mediana (Md): Construído o rol (organização das observações de maneira crescente ou decrescente), o valor de mediana é o elemento que ocupa a posição central, ou seja, é o elemento que divide a distribuição em 50% de cada lado.
- Número de observações (n) ÍMPAR: valor da mediana será o valor central da distribuição (elemento que divide a distribuição em 50% de cada lado).
- Número de observações (n) PAR: valor da mediana será a média aritmética das duas centrais.
Separatrizes: Dividem um conjunto de dados igualmente.
- Quartis: Dividem um conjunto de dados em quatro partes iguais.
- Decis: Valores que devide a série de dados em dez partes iguais.
- Percentis: Valores que divide a amostra em 100 partes iguais. (Essa separatriz será amplamente utilizada quando abordarmos o conceito de z - score e distribuição normal).
Medidas de Dispersão[]
"As medidas de dispersão indicam se as observações estão relativamente próximas uma das outros, ou separadas em torno de uma medida de posição, a média aritmética. Serão estudadas três medidas de dispersão: variância, desvio padrão e coeficiente de variação".
Variância: Média dos quadrados dos desvios dos valores a contar da média. (Variância Populacional: 𝜎^2) (Variância Amostral: S^2). Ver figura abaixo à esquerda.
Desvio Padrão: É a raiz quadrada da variância. O valor do desvio padrão mostra o quanto de "dispersão" existe em relação à média. Um baixo desvio padrão indica que as observações estão pouco desviadas da média, ou próximas dela. Um desvio padrão alto indica que as observações estão muito espalhadas e se distanciam de maneira significativa do valor padrão (média).
Obs: É de suma importância entender integralmente o conceitos média aritmética e desvio padrão. Isso porque serão as bases para o entendimento das distribuições paramétricas e não paramétricas e dos testes estatísticos referentes às distribuições contínuas.
Coeficiente de Variação: Trata-se de uma média relativa à dispersão, útil para comparação e observação em termos relativos do grau de concentração em torno da média de séries distintas. Ver figura abaixo à direita.

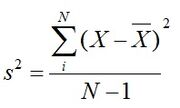
{kind=link}
Fonte: Claiton E. Amaral, 2013 (Anotações da Aula)
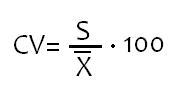
{kind=link}
Fonte: Claiton E. Amaral, 2013 (Anotações da Aula)
Escalas[]
Constituem - se em um elemento estatístico importante para organização das medições feitas em uma determinada amostra. As escalas utilizadas devem - se adequar ao modelo estatístico utilizado pelo pesquisador e aos diferentes tipos de variáveis utilizados por ele.
Escala Contínua: As observações intermediárias não são contáveis por assumirem valores infinitamente distantes umas das outras. (ex: peso em quilogramas).
Escala Discreta: As observações intermediárias são contáveis por assumirem valores finitamente distantes umas das outras. (ex: número de filhos).
Escala Ordinal: Há ordenação inerente às observações, por vezes hierarquização. (ex: classe social).
Escala Nominal: Não há qualquer ordem das observações. (ex: cidade de origem).
Escala Dicotômica. Caso específico de escala nominal em que as observações podem assumir apenas dois valores. (ex: sexo).
Segue, abaixo, uma tabela auxiliar apresentando as indicações de utilização das escalas de acordo com as necessidades do pesquisador e os tipos de observações realizadas por ele:

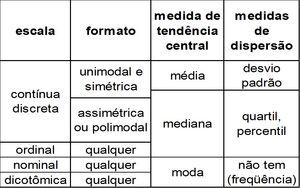
{kind=link}
Fonte: Guilherme Lima, 2013 (Anotações da Aula)
Distribuição Normal - A curva de Gauss[]
A distribuição normal é a distribuição contínua de probabilidade mais importante. Isso porque essa distribuição representa as frequências observadas de muitos fenômenos naturais e físicos. O aspecto do gráfico na forma de sino tem aplicação inquestionável nas mais diversas áreas do conhecimento. A distribuição de Gauss serve também para aproximar outros tipos de dispersões como a binomial.


{kind=link}
Fonte: rudy-gonzalez.blogspot
Propriedades da Distribuição Normal:
a) Representação gráfica associada diretamente à escalas númericas contínuas;
b) O valor central da curva é a média aritmética das observações;
c) A medida que se caminha a direita do valor central (média), os valores desviam positivamente. A medida que se caminha a esquerda do valor central (média), os valores desviam negativamente;
d) A distribuição normal é simétrica em relação à média aritmética das observações;
e) A função da curva assume, como valor máximo, o valor da média aritmética. Ou seja, a moda da distribuição é a média aritmética;
f) A curva de Gauss é SEMPRE unimodal (somente uma moda = média aritmética);
g) A função da curva é duplamente assintótica ao eixo das abcissas (Não toca em momento algum o eixo das abcissas, somente quanto o valor tende ao infinito).
Perceba que quanto mais os valores se distanciam da média (valores muito maiores ou muito menores) o número de ocorrências também diminui. Não é dificil perceber isso em situações cotidianas. Imagine - se, por exemplo, em uma sala de aula com diversos alunos. A média de alturas desses alunos é sempre o valor com maior ocorrência (vamos considerar 1,70m) e aqueles extremamente altos (2,00m) ou extremamente baixos (1,40m) são em número bastante reduzidos, considerados raridades na turma.
Z - Score (Escore Padrão)[]
O z - score ou escore padrão é amplamente utilizado para a comparação das médias de um conjunto diferentes de dados distribuídos de modo homogêneo. O valor númerico obtido a partir do z - score aponta o número de desvios de uma observação e se esses desvios situam - se acima ou abaixo da média. É importante lembrar que o z - score é somente aplicável quando a distribuição segue a curva normal (Gauss). Isto é, aplicável nas distribuições paramétricas.
Para obter o valor z, utiliza - se a fórmula abaixo:

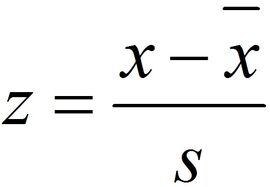
{kind=link}
Fonte: Claiton E. Amaral, 2013 (Anotações da Aula)
Z - score: Nnúmero de desvios acima ou abaixo da média.
X: Observação que se deseja avaliar
X barra: Média de todos os valores observados.
S: Desvio padrão dos valores observados.
Uma vez obtido o valor "z" da fórmula acima pode - se utilizar a tabela Z. Abaixo estão as etapas para a definição da àrea entre o ponto observado e a média (ponto central):
1) Na tabela Z os valores das linhas (porção esquerda da tabela) serão utilizadas para indicar o número e a primeira casa decimal do número Z.
Exemplo 1: Se o número z for 3,54, a linha de interesse será aquela de valor 3,5.
Exemplo 2: Se o número z for 2,5, a linha de interesse será aquela de valor 2,5.
2) Os valores das colunas (porção superior da tabela) indicarão a segunda casa decimal do número Z.
Exemplo 1: Se o número z for 3,54, a coluna de interesse será aquela de valor 4.
Exemplo 2: Se o número z for 2,5, a linha de interesse será aquela de valor 0.
3) Uma vez obtida a região da tabela referente ao número z, deve - se transformar o valor correspondente em áreas percentuais.
Exemplo 1: Se o número z for 3,54, o valor correspondente será 4998. Transformando: 49,98%
Exemplo 2: Se o número z for 2,5, o valor correspondente será 4938. Transformando 49,38%
A porcentagem indicará a área (em porcentagem) abaixo da curva de distribuição entre o ponto observado (X) e a média aritmética (ponto central da curva de Gauss). A figuras abaixo apresentam a tabela z (esquerda) e um desenho esquemático da área abaixo da curva de distribuição normal (direita). Perceba que a unidade da área abaixo do gráfico, em estatística, é dada em porcentagem.


{kind=link}
Fonte: Claiton E. Amaral, 2013 (Anotações da Aula)
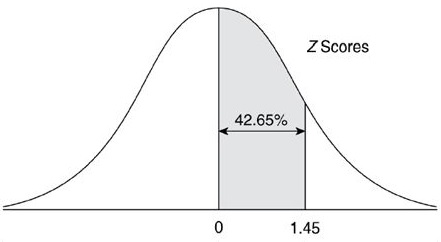
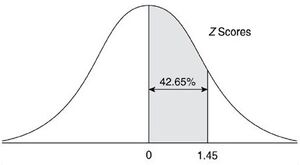
.jpg){kind=link}
Fonte: Claiton E. Amaral, 2013 (Anotações da Aula)
Exercícios e Resoluções:
1) Admitindo uma distribuição normal, a qual percentil corresponde uma criança com peso 1,54 desvios padrões abaixo da média do grupo?
Resolução: Utilizando a tabela z percebe - se que a área entre o valor observado da criança e a média é 43,82%. Lembrando que ela está abaixo da média, 50% - 43,82% = 6,18%. Logo 6,18% das crianças estarão abaixo da criança estudada. Portanto, a criança em questão localiza - se no 7o percentil. (obs: lembre - se que a curva normal é simétrica e que a média divide o gráfico em duas porções iguais 50% à direita e 50% à esquerda).
2) Admitindo uma distribuição normal, se uma amostra de setenta (70) adolescentes tem peso médio de 30,0 quilogramas, e desvio padrão de 3,6 quilogramas. À quantos desvios padrões abaixo da média está uma pessoa com 27,9 quilogramas? A que percentil ela pertence?
Resolução: Calculando através da fórmula o valor z, obtem - se z = 0,58, ou seja, a pessoa está a 0,58 desvios abaixo da média. Utilizando a tabela z percebe - se que a área entre o valor observado e a média é 21,90%. Logo 28,10% das pessoas estão abaixo da estudada. Portanto a pessoa em questão localiza - se no 29o percentil.
Referências[]
1 - ALMEIDA FILHO, Naomar. ‘For a General Theory of Health: preliminary epistemiological and anthropological notes’. Cadernos de Saúde Pública, Rio de Janeiro, 17(4):753-799, jul-ago, 2001.
2 - ALTMAN, Doug et al. Absence of evidence is not evidence of absence. British Medical Journal 1995; 311:485.
3 - AMARAL, Augusto Radünz. Anotações da aula da Disciplina de Epidemiologia Geral. UNIVILLE. 05/06/2013.
4 - CARVALHO, José Mexia Crespo. A lógica da logística. Lisboa: Edições Sílabo, 2004.
5 - CHIZZOTTI, Antonio. Pesquisa em ciência humanas e sociais. São Paulo: Cortez, 2006.
6 - DESCARTES, René. Discurso do método. Tradução, prefácio e notas de João Cruz Costa. São Paulo: Ed de Ouro, 1970.
7 - Dorland's illustrated medical dictionary. 29th ed. Philadelphia: W.B. Saunders; 2000.
8 - GARDNER, Marie, ALTMAN Doug. Confidence intervals rather than P values: estimation rather than hypothesis testing. British Medical Journal (Clin Res Ed) 1986;292(6522):746-50.
9 - GRIMES, David, SCHULZ Kevin. An overview of clinical research: the lay of the land. The Lancet 2002; 359:57-61.
10 - HADDAD, Nagib. Metodologia de estudos em ciências da saúde: como planejar, analisar e apresentar um trabalho científico. São Paulo: Roca, 2004.
11 - LAKATOS, Eva Maria; MARCONI, Marina de Andrade. Metodologia científica. São Paulo: Atlas, 2007
12 - MOORE, David. Statistics for the Twenty-First Century. Washington, DC: The Mathematical Association of America, 1992. 14–25 p
Links Externos
1 - Bioestatística Básica - Medidas de Tendência Central
2 - Conceitos Básicos em Epidemiologia e Bioestatística
3 - Estatística II - Medidas de Posição e Dispersão: Aplicação Prática no Microsoft Excel
4 - Normal Distribution and Z - Score
6 - Understanding Confidence Intervals (CI)
7 - Understandig the p - value